
AI tolkar både bild och text
AI har på senare år blivit allt bättre på att tolka både texter och bilder. Nu har de båda färdigheterna för första gången förenats. Resultatet blir en AI med bättre förståelse av världen.
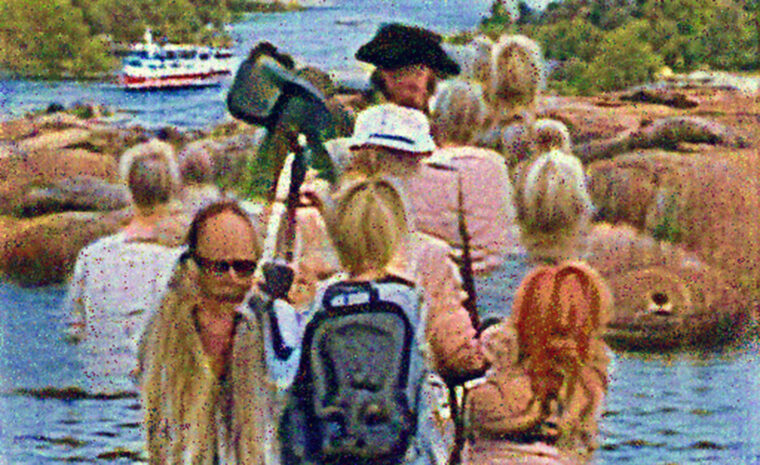
Clip heter en ny AI som kan tolka både text och bild. Här har den skapat en bild utifrån texten: ”ett foto på turister i Stockholms skärgård”.
Bild: Rise Ariel Ekgren, bilden är beskuren
De senaste kraftfulla AI-modellerna för textförståelse har slagit världen med häpnad. De klarar en rad olika uppgifter som att skriva sammanfattningar, klassificera texter, svara på frågor och skriva såväl dataprogram som poesi. Tidigare krävdes modeller som specialtränats för varje uppgift. Även system för bildigenkänning utvecklas åt samma håll.
Nu har för första gången två sådana system för text respektive bild kopplats ihop. Den nya modellen kallas Clip och är utvecklad av forskningsbolaget Open AI i Kalifornien, USA. Clip-modellen lärde sig på egen hand att koppla ihop text och bild med hjälp av 400 miljoner bilder med tillhörande bildtexter som hämtats från internet.
AI kan reagera utifrån kunskap
Enligt Magnus Sahlgren, som leder forskningsgruppen inom språkteknologi på forskningsinstitutet Rise i Stockholm, är ett system som kan förstå både text och bild ett viktigt steg mot en AI med generell intelligens.
– I dag är alla AI specialiserade på en viss uppgift, men målet är att bygga maskiner med mer generell förmåga att kunna lära sig olika slags uppgifter från olika slags data, samt att kunna förstå, resonera, och agera utifrån sin kunskap.
Då räcker det inte att AI-modellen vet hur ordet ”kopp” används i text. Men om ordet också kopplas till en bild av en kopp ökar den sin kunskap om världen.
Magnus Sahlgren tror att Clip bara är början på en utveckling med så kallade multimodala modeller som på sikt förenar alla mänskliga sinnen. Framtidens AI-system kan se, höra och kanske till och med känna.
– Det är bara en tidsfråga. Utvecklingen går väldigt snabbt, säger Magnus Sahlgren.
Liknar mer konst än fotografier
Fredrik Carlsson och Ariel Ekgren, båda AI-forskare på Rise, håller med. På Centrum för tillämpad AI inom Rise har de precis färdigställt en svensk version av Clip. De första testerna visar till exempel att den kan koppla texter som ”ett lila äpple” till en bild på ett lila äpple.
– Det trots att den aldrig tidigare sett texten ”ett lila äpple” eller en bild på ett lila äpple. Det är rätt häftigt, säger Fredrik Carlsson.
Med clip går det även att generera bilder från en text, även på sådant modellen inte tränats för. Ariel Ekgren har testat att låta modellen måla upp bilder utifrån bildtexter som: ”foto på turister i Stockholms skärgård” eller ”en dystopi i färg” (fler exempel finns här). Resultatet blir rätt häpnadsväckande bilder som än så länge mer liknar konst än foton.
Vad skulle det här då kunna användas till?
Forskarna på Rise ser flera tillämpningar. En är att klassificera bilder, något som i dag ofta sker manuellt genom att en bild märks upp efter innehåll. Det blir också möjligt att göra avancerade sökningar i bilder som inte är uppmärkta på förhand. I förlängningen skulle en AI kunna illustrera texter helt automatiskt.
– Vi skulle till och med kunna automatgenerera ett helt litterärt verk och även illustrera det, säger Magnus Sahlgren.






































