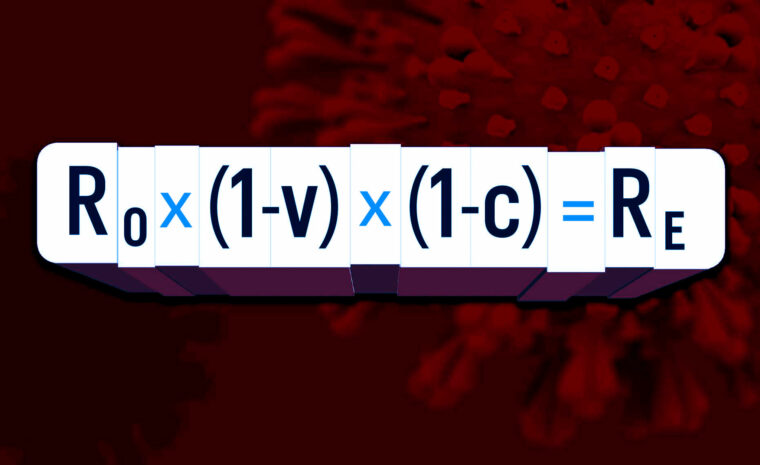Därför är det svårt att modellera smittan
Över hela världen jobbar forskare med att utveckla modeller över hur smitta sprids. Men osäkerhetsfaktorerna är många och resultaten svåra att tolka.

”Modeller är inte kristallkulor”.
Bild: Getty images
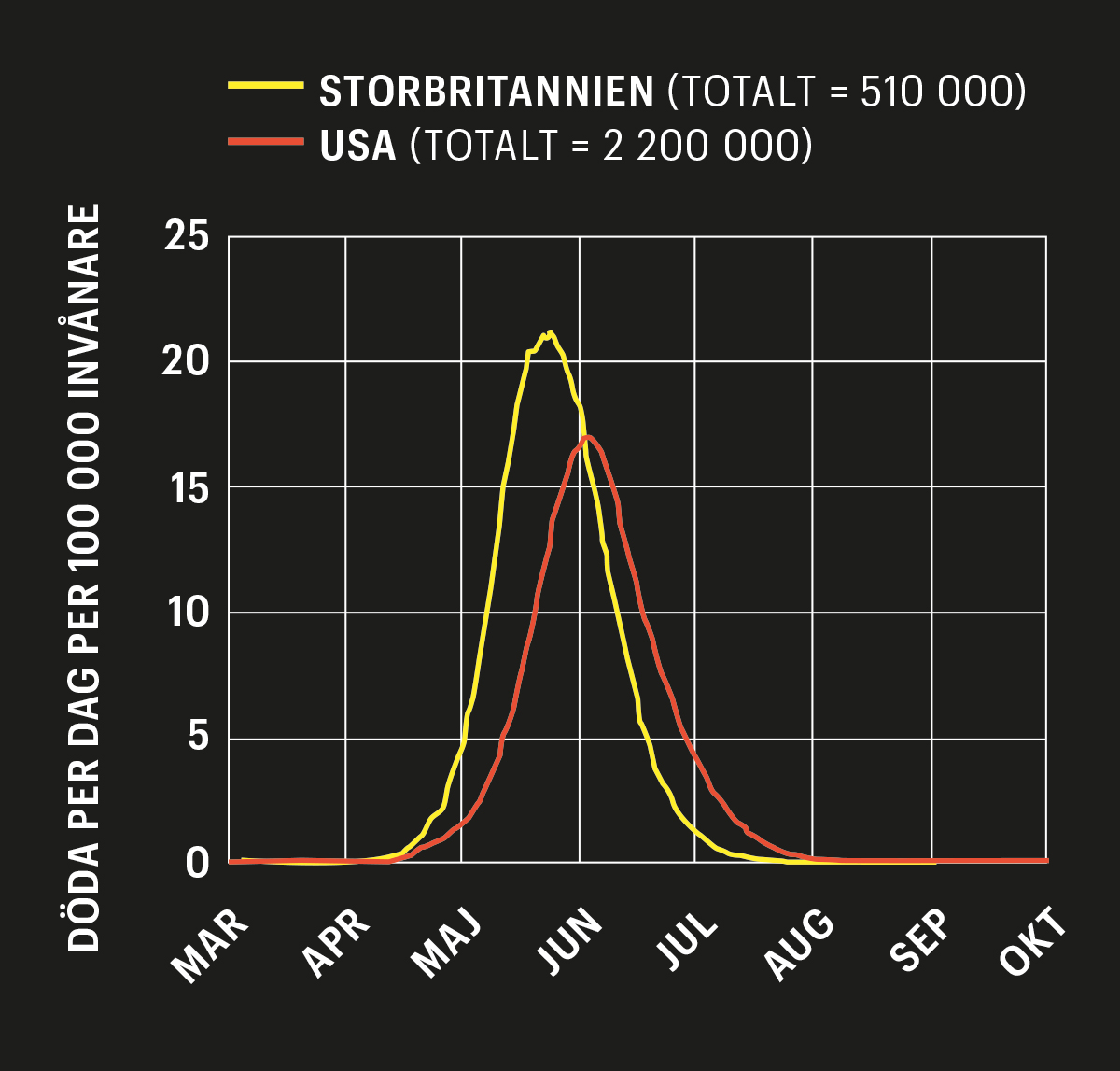
I mitten av mars publicerade forskare vid Imperial College i London en simulering som visade att om Storbritannien inte vidtog några åtgärder skulle en halv miljon människor kunna dö i covid-19. Simuleringsrapporten bidrog starkt till att landet införde strängare restriktioner.
Huvudförfattaren Neil Ferguson är en av världens ledande forskare inom matematisk epidemiologi och från hans grupp kommer en strid ström av modellstudier av det nya viruset. Även i andra länder använder forskare och myndigheter olika modeller för att förstå spridningen och utvärdera olika åtgärder.
Men eftersom det fortfarande saknas viktig information om viruset sars-cov-2, bygger modellerna på antaganden. Simulerade modeller ska därför inte tas för prognoser över framtiden.
– Vi bygger förenklade representationer av verkligheten. Modeller är inte kristallkulor, säger Neil Ferguson i en intervju med tidskriften Nature.
Reproduktionstalet viktig parameter
Epidemiologiska modeller används både för smittspridning och för att till exempel planera vaccinationskampanjer. En vanlig modell kallas SEIR. Förenklat bygger den på att befolkningen delas in i fyra grupper: mottagliga för smitta, exponerade, smittbärare och de som har haft sjukdomen och antingen tillfrisknat eller avlidit. I modellen flyttas personer mellan grupperna med hjälp av ekvationer, som i sin tur innehåller parametrar för den aktuella smittan. En viktig sådan är det så kallade reproduktionstalet, som anger hur många en smittad person smittar i genomsnitt. Andra parametrar är genomsnittlig inkubationstid, sjukdomstid och antalet fysiska kontakter.
När befolkningen i modellen ”smittats” flyttas personer mellan de olika grupperna enligt ekvationerna.
För att bli mer realistisk byggs ofta modellen ut för att till exempel även inkludera personer i karantän och åtgärder för att minska smittspridning, som social distansering. Infekterade kan delas in i de som har milda symtom och personer som behöver sjukhusvård respektive intensivvård. Befolkningen kan delas upp i åldersgrupper och efter var de bor. Även resemönster och sociala kontakter finns med i modellen. För att mer likna verkligheten går det också att föra in en viss grad av slumpmässighet.
Rocklöv modellerade smittan i Sverige
Joacim Rocklöv, professor i epidemiologi vid Umeå universitet, har med sin forskargrupp byggt en avancerad SEIR-modell över coronavirusets spridning i Sverige. Data över åldersfördelning och geografisk fördelning har hämtats från Statistiska centralbyrån, SCB. Den tar hänsyn till resemönster och delar in de infekterade i olika grupper, från opåverkade till de som behöver intensivvård.
Modellen har använts för att simulera hur behovet av intensivvårdsplatser ändras beroende på graden av social distansering. Resultatet visar att utan social distansering skulle IVA-platserna i Sverige inte räcka till.
– Vi reviderar nu den första modellen för att anpassa den till det vi vet om smittspridningen i Sverige. Vi försöker också att väga in faktorer som skiljer Sverige från andra länder, exempelvis hur sjukvården är uppbyggd och hur vi utnyttjar den, säger Joacim Rocklöv.
En stor utmaning för alla som bygger modeller är de många osäkerhetsfaktorerna. Hur detaljerad modellen än är så blir resultatet ändå missvisande om den matas med fel indata. Och osäkerheten är fortfarande stor kring många av de parametrar som styr smittspridningen.
Eftersom få hittills har testats vet ingen hur många som har haft sjukdomen. Det gör att det är svårt att avgöra den totala dödligheten. Imperial College räknade i mitten av mars med en dödlighet på 0,9 procent.
– I vår modell uppskattar vi att den ligger betydligt lägre, runt 0,4 procent, baserat på preliminära serologiska resultat (tester som visar förekomst av antikroppar i blodet, reds anm), säger Joacim Rocklöv när detta skrivs i slutet av april.
Modeller kan belysa osäkerheten
Andra osäkra parametrar är hur smittsamt viruset är hos personer med milda eller inga symptom. En annan fråga är om alla som har haft sjukdomen utvecklar antikroppar och blir immuna, och i så fall för hur lång tid. Även huruvida virusspridningen kommer att mattas av på sommaren och vilken betydelse så kallade superspridare har, är frågor som behöver undersökas vidare.
– I början av ett utbrott finns inte så mycket information. Vi tar det bästa vi har, förenklar och använder sannolikhetsfördelningar för att hantera osäkerheten, säger Joacim Rocklöv.
Han säger att modeller kan vara ett verktyg för att belysa osäkerheten i smittspridningen. Genom känslighetsanalyser, många körningar där indata ändras lite mellan varje körning, går det att avgöra hur viktig en viss faktor är för sjukdomens spridning. En sådan faktor är till exempel symtomfri smitta.
Modellerna blir viruella experimentvärldar
Modellerna kan också användas för att simulera olika scenarier. Till exempel går det att utforska vad som händer när kontakten mellan människor minskar. En lika viktig fråga är hur spridningen påverkas när kontakterna ökar, när tidigare stängda samhällen öppnar.
– Vi kan använda modellerna som virtuella experimentvärldar, säger Joacim Rocklöv.
Modeller och simuleringar används inom många områden och tekniken går raskt framåt. Inom industrin används allt mer avancerade modeller för att spegla verkligheten. Genom att koppla upp maskiner och robotar kan den virtuella modellen uppföra sig precis på samma sätt som till exempel en fysisk fabrik.
På liknande sätt skulle datormodeller över smittspridning i framtiden kunna bygga på hur personer verkligen rör sig i samhället, via appar i mobilen eller data från sociala medier. En utmaning är att insamlingen av data inte samtidigt inkräktar på den personliga integriteten.